#!/usr/bin/env python3
# encoding: utf-8
# api: cli
# type: filter
# title: dingonyms
# description: fetch synonyms from various web services
# version: 0.8
# license: PD
# category: dictionary
# keywords: glossary, synonyms, antonyms
# classifiers: search, dict
# architecture: all
# depends: deb:ding (>= 1.8), python (>= 3.6), python:requests (>= 2.4)
# url: https://fossil.include-once.org/pagetranslate/wiki/dingonyms
# doc-format: text/markdown
#
# CLI tool to extract synonyms/antonyms from online services, which formats
# them into dict structures (`word|alt :: definition; etc.`) suitable for
# [`ding`](https://www-user.tu-chemnitz.de/~fri/ding/).
#
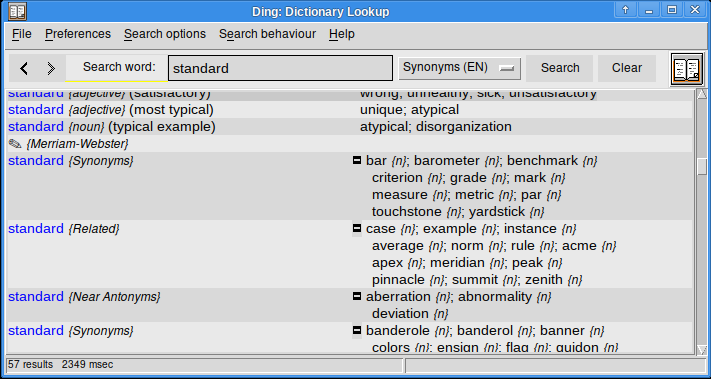
# 
#
# It's fairly basic, and not all result sets are structured alike.
# Furthermore the extraction schemes aren't likely to last for long (web
# scraping is typically a maintenance task).
# Only scans for singular words (most services wouldn't return results
# otherwise). And might yield error messages for charset issues as well.
#
# ### SYNTAX
#
# > dingonyms --merriamwebster "find"
#
# | Parameter | Aliases | Class |
# |-------------------|---------------------------------------------|-------|
# | \--thesaurus | -t --thes | EN |
# | \--merriamwebster | -mw --merr \--webster \--merweb | EN |
# | \--synonym | -s --syn -\-synonym.com | EN |
# | \--reverso | \--rev // -fr -es -it -pt -nl -ru -jp | EN/\**|
# | \--wordhippo | -hippo --wordhip | EN |
# | \--mobythesaurus | -mby --moby | EN |
# | \--urban | -u --urb \--ubn |LEXICON|
# | \--dictcc | --en-es --en-it --de-fr --en-pt | DICT |
# | \--openthesaurus | -ot \--othes --open | DE |
# | \--woxikon | -wx \--woxi | DE |
# | \--synonyme_de | -sd --desyn | DE |
# | \--all | (-t -mw -syn -rev -ot -wx -urban) | MIXED |
# | \--en | (-t -mw -syn -rev) | MIXED |
# | \--de | (-ot -wx -sd) | MIXED |
# | \--no-antonyms | -na | FLAG |
# | \--no-headers | -nh | FLAG |
# | \--async | \--parallel \--io | FLAG |
#
# Flags can be abbreviated and also combined: `--thes --merrweb` would query two
# services at once, or `--all` even all. While `--en` or `--de` run through language-
# specific functions; and `--parallel` speeds up fetching, but may mangle output.
# See the man page for more details. (There is a man page.)
#
# ### CONFIG IN ~/.dingrc (take care to change `3` to available index)
#
# > set searchmeth(3,name) {Synonyms (EN)}
# > set searchmeth(3,type) {3}
# > set searchmeth(3,dictfile) {}
# > set searchmeth(3,separator) { :: }
# > set searchmeth(3,language1) {Group}
# > set searchmeth(3,language2) {Synonyms}
# > set searchmeth(3,grepcmd) {dingonyms}
# > set searchmeth(3,grepopts) {--async --thesaurus --merriamwebster --wordhippo}
# > set searchmeth(3,maxlength) {30}
# > set searchmeth(3,maxresults) {200}
# > set searchmeth(3,minlength) {2}
# > set searchmeth(3,shapedresult) {1}
# > set searchmeth(3,foldedresult) {0}
#
# You might want to add one entry for each search backend even.
# (Unique index, title/name, and grepopts --parameter each.)
#
# ### SETUP (pip3 install -U dingonyms)
#
# You might have to symlink `~/.local/bin/dingonyms` into `~/bin` after
# installation. pip-package binaries are often only picked up in
# terminal/interactive shells.
#
# ### Hijack as module
#
# Obviously this is primarily a CLI tool, but can be utilized per monkeypatching:
#
# > import dingonyms
# > ls = []
# > dingonyms.out.alternatives = lambda *x: ls.append(x)
# > dingonyms.lookup.merriamwebster("ornate")
#
# Notably a few more out.* methods could require overriding.
#
import sys, os, asyncio, re
import requests, json, html, textwrap
try:
sys.stdout.reconfigure(encoding="utf-8")
except:
pass# and pray
def http_get(url):
""" fetch page per requests GET, add user-agent header """
return requests.get(
url,
headers={"User-Agent":"dingonyms/0.8 (Python 3.x; Linux; CLI/ding; +https://pypi.org/projects/dingonyms)"},
timeout=3
).text
class out:
""" output utility functions """
no_antonyms = False
no_headers = False
@staticmethod
def fold(wordlist):
""" Wrap list of words acrosss multiple lines, conjoin ~45 chracters of words in each """
rows = []
line = []
for w in wordlist:
if len("; ".join(line + [w])) > 45:
rows.append("; ".join(line))
line = []
line.append(w)
if line:
rows.append("; ".join(line))
return rows
@staticmethod
def alternatives(title, wordlist, fold=True):
""" craft `Word :: Synonyms` lines """
if fold:
wordlist = out.fold(wordlist)
title = re.sub("([^|]{45,55})\\b(?=.*\w)", "\\1 |", title)
title = re.sub("[\\x00-\x1F]", "", title)
#print(f"==={title}===")
if out.no_antonyms and re.search("\{Ant|\{Near|🞬|❙", title, re.U):
return
pipes = len(wordlist) - len(title.split("|"))
title = title + (" |" * pipes)
print(
re.sub(
"[\\x00-\x1F]", "",
f"{title} :: {' | '.join(wordlist)}"
)
)
@staticmethod
def site(name):
""" output prefix for online service """
if out.no_headers: return
print(f"✎ {'{'+name+'}'}")
@staticmethod
def group(name="Antonyms"):
""" section prefix """
print(f"❙ {'{'+name+'}'} ❙")
@staticmethod
def unhtml(text):
""" crude html2text for urbandictionary flow text """
text = re.sub("\s+", " ", text)
text = re.sub("<br>|</div>", "\n", text, re.I)
text = re.sub("(<[^<]+(>|$))+", " ", text)
return re.sub(" +", " ", html.unescape(text))
class lookup:
"""
Online service backends and extraction.
Not much of a real object, just a function collection.
Docblock of each function starts with a --param regex.
"""
def __init__(self):
pass
def run(self, callback, *a, **kw):
""" stub for non-threaded calls, simply invokes callback right away """
return callback(*a, **kw)
def set_no_antonyms(self, *a):
""" no-antonyms | no | na | no-?an?t?o?\w* | Avoid printing antonyms/related sections """
out.no_antonyms = True
def set_no_headers(self, *a):
""" no-headers | nh | no-?he?a?d?\w* | No section headers """
out.no_headers = True
def set_async(self, *a):
""" async | a?io | thread\w* | parallel\w* | Run queries in parallel """
# Just redefines self.run() to utilize asyncio threads (not real async task→result schemes)
threads = asyncio.get_event_loop()
def run(callback, *a, **kw):
threads.run_in_executor(None, lambda: callback(*a, **kw))
self.run = run
return threads # not even needed
def thesaurus_raw(self, word, lang=None, html=""):
""" thesaurus-?(raw|htm) | raw | htm | Open Thesaurus (regex) """
if not html:
html = http_get(f"https://www.thesaurus.com/browse/{word}")
ls = []
grp = "synonym"
# look for word links, or grouping divs (not many reliable html structures or legible class names etc.)
rx = ''' "/browse/([\w.-]+)" | <div\s+id="(meanings|synonyms|antonyms|[a-z]+)" | (</html) '''
for add_word, set_grp, endhtml in re.findall(rx, html, re.X):
if add_word:
ls.append(add_word)
elif ls:
out.alternatives(f"{word} {'{'+grp+'}'}", ls)
ls = []
if set_grp:
grp = set_grp
def thesaurus(self, word):
""" thesaurus |t | t[he]+s[saurus]* | Open Thesaurus (JSON) """
html = http_get(f"https://www.thesaurus.com/browse/{word}")
out.site("Thesaurus.com")
# there's a nice pretty JSON blob inside the page
try:
m = re.search("INITIAL_STATE\s*=\s*(\{.+\})[;<]", html)
j = json.loads(re.sub('"\w+":undefined,', '', m.group(1)))
for grp in "synonyms", "antonyms":
if grp == "antonyms":
if out.no_antonyms:
return
out.group("Antonyms")
for d in j["searchData"]["relatedWordsApiData"]["data"]:
if grp in d and len(d[grp]):
out.alternatives(
"%s {%s} (%s)" % (d["entry"], d["pos"], d["definition"]),
[word["term"] for word in d[grp]]
)
except:
out.group("failed JSON extraction")
self.thesaurus_raw(word, html=html)
def openthesaurus(self, word):
""" api | openthesaurus | open | ot | ope?nt\w* | Open Thesaurus (API) """
# there's a proper API here
j = json.loads(
http_get(f"https://www.openthesaurus.de/synonyme/search?q={word}&format=application/json&supersynsets=true")
)
out.site("OpenThesaurus.de")
for terms in j["synsets"]:
supersyn = ""
if terms["supersynsets"] and terms["supersynsets"][0]:
supersyn = "; ".join([w["term"] for w in terms["supersynsets"][0]][0:3])
supersyn = "("+supersyn+")"
out.alternatives(
f"{word} {supersyn}",
[w["term"] for w in terms["terms"]]
)
def woxikon(self, word):
""" woxikon | w | wx | wxi?k\w* | Woxikon (German) """
html = http_get(f"https://synonyme.woxikon.de/synonyme/{word}.php")
out.site("Woxikon.de")
ls = []
rx = ''' <a\s+href="[^"]+/synonyme/[\w.%-]+">(\w[^<]+)</a> | Bedeutung:\s+<b>(\w[^<]+)< | </html '''
for add_word, grp in re.findall(rx, html, re.X):
if add_word:
ls.append(add_word)
elif ls:
out.alternatives(f"{word} ({grp})", ls)
ls = []
def synonyme_de(self, word):
""" synonyme.de | synonyme[_\-.]?de | sd | de[_-]?syn\w* | Synonyme.de (German) """
html = http_get(f"https://www.synonyme.de/{word}/")
out.site("Synonyme.de")
ls = []
rx = '''
<span><b>(\w[^<]+)</b>\s+-\s+Bedeutung\s+für\s+(\w\S+)\s+\((\w+)\) |
<p><span>\s*(Sonstige\s\d+) |
<a\s+href="/\w[^/">]+/">\s*(\w\S+)\s*</a> |
</html>
'''
for set_grp, set_word, verb, grp, add_word in re.findall(rx, html, re.X):
if add_word:
ls.append(add_word)
elif ls:
out.alternatives(word, ls)
ls = []
if set_grp or verb:
word = f"{set_word} {'{'+verb[0].lower()+'}'} ({set_grp})"
elif grp:
word = f"{set_word} ({grp})"
def merriamwebster(self, word):
""" merriam-?webster | mw | mer\w* | m\w*w\*b\w* | \w*web\w* | Merriam Webster """
html = http_get(f"https://www.merriam-webster.com/thesaurus/{word}")
#print(html)
out.site("Merriam-Webster.com")
ls = []
grp = "Synonyms"
# word links here are decorated with types (noun/verb), and groups neatly include a reference to the search term (or possibly a different related term)
rx = ''' href="/thesaurus/([\w.-]+)">(\w+) | ="function-label">(?:Words\s)?(Related|Near\sAntonyms|Antonyms|Synonyms|\w+)\s\w+\s<em>([\w.-]+)</em> | (</html) '''
for add_word, verb, set_grp, set_word, endhtml in re.findall(rx, html, re.X):
#print(row)
if add_word:
ls.append("%s {%s}" % (add_word, verb[0]))
elif ls:
out.alternatives(word + " {%s}" % grp, ls)
ls = []
if set_grp or set_word:
grp, word = set_grp, set_word
def synonym_com(self, word):
"""
synonym | synonyms?([._\-]?com)?$ | s$ | sy$ | sy?n\w*\\b(?<!de) |
Synonym.com doens't provide a rich result set.
"""
html = http_get(f"https://www.synonym.com/synonyms/{word}")
html = re.sub('^.+?="(tabbed-header|content-container)">', "", html, 0, re.S)
html = re.sub('<div class="rightrail-container">.+$', "", html, 0, re.S)
# print(html)
out.site("Synonym.com")
rx = """
<h4\sclass="section-list-header">([\w\s-]+)</h4> |
<li[^>]*>\s*(?:<a[^>]+>)? \s*([^<>]+)\s* (\(.+?\))? \s*(?:</a>)?\s*</li> |
(</html>)
"""
ls = []
pfx = word + " {Synonyms}"
for group, add_word, defs, html in re.findall(rx, html, re.X|re.S):
if add_word:
ls.append(add_word)
else:
if ls:
out.alternatives(pfx, ls)
ls = []
if group:
pfx = word + " {" + group + "}"
continue
#defs = re.sub('(<[^>]+>|\s+)+', " ", defs, 0, re.S).strip()
#defs = " | ".join(textwrap.wrap(defs, 50))
#pfx = group + " {" + verb + "} [" + pron + "] | (" + defs + ")"
def urban(self, word):
""" urban | u | u\w*[brn]\w* | Urban Dictionary """
html = http_get(f"https://www.urbandictionary.com/define.php?term={word}")
out.site("UrbanDictionary.com")
for html in re.findall('="def-panel\s*"[^>]*>(.+?)="contributor|def-footer">', html, re.S):
if re.search('<div class="ribbon">[\w\s]+ Word of the Day</div>', html):
continue
else:
html = re.sub('^.+?="def-header">', "", html, 1, re.S)
m = re.search('<a class="word" href="/define.php\?term=\w+" name="\w+">([\w.-]+)</a>', html)
if m:
word = m.group(1)
html = re.sub("^.+?</a>", "", html, re.S)
text = out.unhtml(html)
if not text:
continue
# at this point, it's becoming custom output to wrap flow text into Tk/ding window
text = re.sub("^[\s|]+", "", text)
text = textwrap.wrap(text, 45)
print(f"{word} {' | '*(len(text)-1)} :: {'|'.join(text)}")
def moby(self, word):
"""
moby-thesaurus | mo?by? | mobyth\w* | Moby Thesaurus
"""
html = http_get(f"https://www.moby-thesaurus.org/{word}")
out.site("Moby-Thesaurus.org")
rx = """
<h2>\s*(?:\d+(?: )?\s*)?(See\salso|(?!\d)\w+)[^<]*</h2> |
<li>\s*<a[^>]+>(\w+[^<]*)</a> |
(</html>)
"""
grp = word + " {Synonyms}"
ls = []
for h2, txt, html in re.findall(rx, html, re.S|re.X|re.I):
if ls and (h2 or html):
out.alternatives(grp, ls)
ls = []
if h2:
grp = word + " {" + h2 + "}"
if txt:
ls.append(txt)
def wordhippo(self, word):
"""
hipp?o? | wordhi\w+ | WordHippo
"""
html = http_get(f"https://www.wordhippo.com/what-is/another-word-for/{word}.html")
out.site("WordHippo.com")
out.alternatives(
word + " {Context}",
re.findall("""<a\sclass="thesaurusContentLink"[^>]*>([^<>]+)</a>""", html)
)
rx = """
<div\sclass="tabdesc">([^<>]+)</div> |
<div\sclass="wb"\s*>\s*<a[^<>]+>([^<>]+)</a>\s*</div> |
(</html>)
"""
grp = word
ls = []
for h2, txt, html in re.findall(rx, html, re.S|re.X|re.I):
if ls and (h2 or html):
out.alternatives(grp, ls)
ls = []
if h2:
grp = word + " (" + h2 + ")"
if txt:
ls.append(txt)
def reverso(self, word, lang="en"):
"""
reverso | re?v\w* |
Interesting, has synonyms for additional languages.
"""
if not re.match("^(nl|it|jp|fr|es|pt)$", lang):
lang = "en"
html = http_get(f"https://synonyms.reverso.net/synonym/{lang}/{word}")
out.site("Reverso.net")
rx = """
="words-options.*?<p>(\w+)</p> |
<a\shref="/synonym/\w+/([\w.-]+)" |
<p>(Antonyms):</p> |
(</html>)
"""
grp = word
ls = []
for set_verb, add_word, antonyms, endhtml in re.findall(rx, html, re.X|re.S|re.U):
if add_word:
ls.append(add_word)
elif ls:
out.alternatives(grp, ls)
ls = []
if antonyms:
grp = "🞬 " + grp + " ❙ {Antonyms}"
if set_verb:
grp = word + " {%s}" % set_verb
def dictcc(self, word, lang="www"):
""" dictcc | cc | (en|de)[-_/:>]+(\w\w) | dict.cc allows language pairs to be given (--fr-it). """
lang = re.sub('\W', '', lang)
if not re.match("^(en|de)(en|de|sv|is|ru|ro|fr|it|sk|pt|nl|hu|fi|la|es|bg|hr|no|cs|da|tr|pl|eo|sr|el|sk|fr|hu|nl|pl|is|es|sq|ru|sv|no|fi|it|cs|pt|da|hr|bg|ro)", lang):
lang = "www"
html = http_get(f"https://{lang}.dict.cc/?s={word}")
out.site("dict.cc")
rx = """
<td[^>]*> (<(?:a|dfn).+?) </td>\s*
<td[^>]*> (<(?:a|dfn|div).+?) </td></tr>
| ^var\dc\dArr = new Array\((.+)\) # json list just contains raw words however
| (<div\sclass="aftertable">|</script><table)
"""
for left,right,json,endhtml in re.findall(rx, html, re.X|re.M):
if endhtml:
break
out.alternatives(
"| ".join(textwrap.wrap(out.unhtml(left), 50)),
textwrap.wrap(out.unhtml(right), 50)
)
def all(self, word):
""" all | a | Run through most (not all) available services """
run = [self.thesaurus, self.merriamwebster, self.synonym_com, self.reverso, self.openthesaurus, self.woxikon, self.moby, self.wordhippo, self.urban]
[m(word) for m in run]
def en(self, word):
""" en | english | All English dictionaries """
run = [self.thesaurus, self.merriamwebster, self.wordhippo, self.synonym_com, self.reverso, self.moby]
[m(word) for m in run]
def de(self, w):
""" de | german | All Germand dictionaries """
run = [self.openthesaurus, self.woxikon, self.reverso, self.synonyme_de]
[m(word) for m in run]
def help(self, *w):
""" ^h$ | help | print syntax and flags """
print("Syntax:\n dingonyms [--backend] word")
#print(""" dictcc en-fr -- "word" """)
print("Flags:")
for name, method, doc in self._methods():
# lazy regex extraction of primary --parameter and |trailing explanation
flag = re.findall("\s*([\w\-.]+)\s*\|", doc)
help = re.findall("\|\s*(\w+\s*[^|]+(?<!\s))\s*$", doc)
if flag:
print(f" --{flag[0]:15}\t{help[0] if help else ''}")
def setup(self, *w):
""" setup | (setup-?)?ding[rc]* | Configure ~/.dingrc with an entry """
conf_fn = os.path.expanduser("~/.dingrc")
conf = open(conf_fn).read()
num = int(re.findall("^set searchmpos \{.+?\s(\d)\}", conf, re.M)[0]) + 1
flags = dict(
name = "Synonyms (EN)",
type = "0",
dictfile = "",
separator = " :: ",
language1 = "Group",
language2 = "Synonyms",
grepcmd = "dingonyms",
grepopts = "--async --thesaurus --merriam --hippo --moby",
maxlength = "30",
maxresults = "200",
minlength = "2",
shapedresult = "1",
foldedresult = "0"
)
add = "".join(
f"set searchmeth({str(num)},{key}) {'{'+val+'}'}\n" for key,val in flags.items()
)
conf = re.sub("(^set searchmpos[^\}]+)", "\\1 "+str(num), conf, 1, re.M)
conf = re.sub("(.+^set searchmeth.+?$)", "\\1\\n" + add, conf, 1, re.S|re.M)
open(conf_fn, "w").write(conf)
def _methods(self):
# shorthand iterator
for name, method in vars(lookup.__class__).items():
yield name, method, method.__doc__ or method.__name__
# instantiate right away
lookup = lookup()
# entry_points for console_scripts
def __main__():
if len(sys.argv) == 1:
return print("Syntax :: dingonyms --site word")
word = "search"
methods = []
# separate --params from search word
for arg in sys.argv[1:]:
if not arg or arg == "--":
continue
elif not re.match("[/+\–\-]+", arg):
word = arg
else:
for name, method, rx in lookup._methods():
# match according to method name or regex in docstring
m = re.match(f"^ [/+\–\-]+ ({rx}) $", arg, re.X|re.I|re.U)
if m:
methods.append((name, m.group(1).lower())) # list of method names and --param
if not methods:
methods = [("thesaurus","-t")]
# invoke method names, potentially after --async got enabled (this is actually
# a workaround to prevent --all from doubly running in the thread pool)
def run_methods(name_and_param, word):
is_async=False
for name, param in name_and_param:
callback = getattr(lookup, name)
args = [word]
if callback.__code__.co_argcount == 3: # pass --lang param where supported
args.append(param)
if is_async and name not in ("all", "de", "en"):
args.insert(0, callback)
callback = lookup.run
if callback:
callback(*args)
if name == "set_async":
is_async = True
run_methods(methods, word.lower())
def dictcc():
bin, lang, *word = sys.argv # syntax: dictcc en-fr -- "word"
if word:
word = [w for w in word if not w.startswith("-")][0]
else:
word, lang = lang, "www"
lookup.set_no_headers()
lookup.dictcc(word, lang)
if __name__ == "__main__":
__main__()